Oscar J. Pellicer Valero, de la VI promoción de la ELU, investigador doctor en el Image Processing Lab en la Universitat de València, nos introduce al mundo de los modelos de inteligencia artificial Generative Pre-Trained Transformer (GPT) y su historia, incidiendo en el peso que han adquirido en los últimos años y, sobre todo, el lugar podrían llegar a ocupar en un futuro no tan lejano.
Disclaimer: En la redacción de este artículo no se ha utilizado ninguna inteligencia artificial (IA) para la generación de la idea original, del contenido o para redacción. Se ha utilizado IA para la traducción de algunos fragmentos del inglés, y para la generación de una de las imágenes.
El pasado 22 de marzo, varios investigadores (incluyendo a Yoshua Bengio y Stuart Rusell, padres del campo de la IA) y reconocidas personalidades en el campo (como Elon Musk o Steve Wozniak) publicaron una carta abierta pidiendo poner pausa el entrenamiento de Large Language Models (LLMs), debido al riesgo existencial que suponen para la humanidad1. Al margen de que muchos de los firmantes (así como la web que acoge dicha carta) se acogen a la filosofía del longtermism2, una versión moderna -y mucho más peligrosa- de la filosofía del bien común, el contenido de la carta en sí plantea una cuestión altamente relevante: “La IA avanzada podría representar un cambio profundo en la historia de la vida en la Tierra, y debería planificarse y gestionarse con el cuidado y los recursos correspondientes3. Lamentablemente […], en los últimos meses los laboratorios de IA se han enzarzado en una carrera fuera de control para desarrollar y desplegar mentes digitales cada vez más poderosas que nadie -ni siquiera sus creadores- puede entender, predecir o controlar de forma fiable”1.
Ian Hogarth escribía en abril en el Financial Times: “Un acrónimo de tres letras no capta la enormidad de lo que representaría la AGI [Inteligencia Artificial General], así que me referiré a ella como lo que es: IA divina. Un ordenador superinteligente que aprende y se desarrolla de forma autónoma, que comprende su entorno sin necesidad de supervisión y que puede transformar el mundo que le rodea. Para ser claros, aún no hemos llegado a este punto. Pero la naturaleza de la tecnología hace que sea excepcionalmente difícil predecir con exactitud cuándo llegaremos a ese punto. La IA divina podría ser una fuerza más allá de nuestro control o comprensión, que podría provocar la obsolescencia o la destrucción de la raza humana.”4
Puede parecer que estamos aún muy lejos de algo así (y es probable que lo estemos), pero el crecimiento exponencial que está sufriendo esta tecnología hace efectivamente imposible predecir su futuro, incluso el más cercano. Un concepto que se baraja habitualmente al hablar en estos términos es el de la singularidad de la IA, propuesto por primera vez por el matemático y físico John von Neumann en 1957, y que hace referencia al punto en el que una inteligencia artificial alcanza un intelecto similar al humano; desde ese momento, tal IA sería capaz de mejorarse a sí misma de forma recursiva, poniendo por ejemplo a un enorme número de IAs iguales a trabajar simultáneamente en el problema de automejorarse. Esta IA acabaría diseñando una IA más inteligente, la cual a su vez diseñaría IAs aún más inteligentes, dando lugar a una explosión de inteligencia. Hay muchos matices y críticas que podrían hacerse a la idea de la singularidad, desde la propia definición de inteligencia, a su dependencia de servidores físicos extremadamente costosos de adquirir y mantener, o la limitación en su influencia sobre el mundo físico, etc. En realidad, como se discutirá más adelante, los avances que se han sucedido en apenas unos pocos meses apuntan a que estamos mucho más cerca de lo que pensamos.
De forma muy esquemática, la revolución de la IA comenzó en 2012, con Geoffrey E. Hinton obteniendo mejoras sin precedentes en clasificación de imágenes gracias al desarrollo de las redes neuronales convolucionales profundas5, al comienzo del uso de GPUs para entrenar modelos mucho más rápido y, en general, con la disponibilidad masiva de datos para entrenamiento. En 2017, investigadores de Google propusieron una nueva arquitectura de IA, el transformer, que mejoraba sustancialmente los resultados en tareas de procesamiento de lenguaje natural, una compleja y hasta entonces elusiva tarea6. Saltando al mes de marzo de 2023, OpenAI presenta GPT-47 , una IA que utiliza la arquitectura transformer, pero que se estima que contiene (la cifra no se ha hecho pública) en torno a 100 billones -millones de millones- de parámetros (vs. los 200 millones que tenía el transformer original), y que está entrenada en todo el texto (e imágenes) del que sus creadores han podido echar mano mediante web scraping. Para que nos entendamos, un parámetro sería -salvando muchas distancias- comparable a una conexión neuronal en una red neuronal natural (esto es, un cerebro); se estima que el cerebro humano tiene en torno a 60 billones de parámetros.
GPT significa Generative Pre-Trained Transformer, lo cual hace referencia a cómo se entrenan estos modelos. A saber: se les proporciona como entrada un texto, o más propiamente, una lista de tokens (que son una representación latente aproximadamente asimilable a una palabra, o a una parte de ella), y deben generar el siguiente token (es decir, la siguiente palabra). El concepto de preentrenamiento (pre-trained) hace referencia al hecho de que estos modelos primero se entrenan en un conjunto enorme de datos textuales, sin una tarea específica más que la de predecir el siguiente token, y después son ajustados (fine-tuned) para realizar tareas concretas más útiles. El ejemplo paradigmático es Chat-GPT, que se desarrolla a partir de un GPT (GPT-3.5-Turbo o GPT-4) pre-entrenado de forma no supervisada (unsupervised learning), pero que luego se ajusta de forma supervisada (supervised fine-tuning) aprendiendo de ejemplos de conversaciones tipo chatbot generadas por humanos; finalmente, se utiliza aprendizaje por refuerzo con realimentación humana (RLHF) para acabar de ajustar el modelo en base a las valoraciones que han dado seres humanos a sus interacciones con el bot, creando así el producto final8.
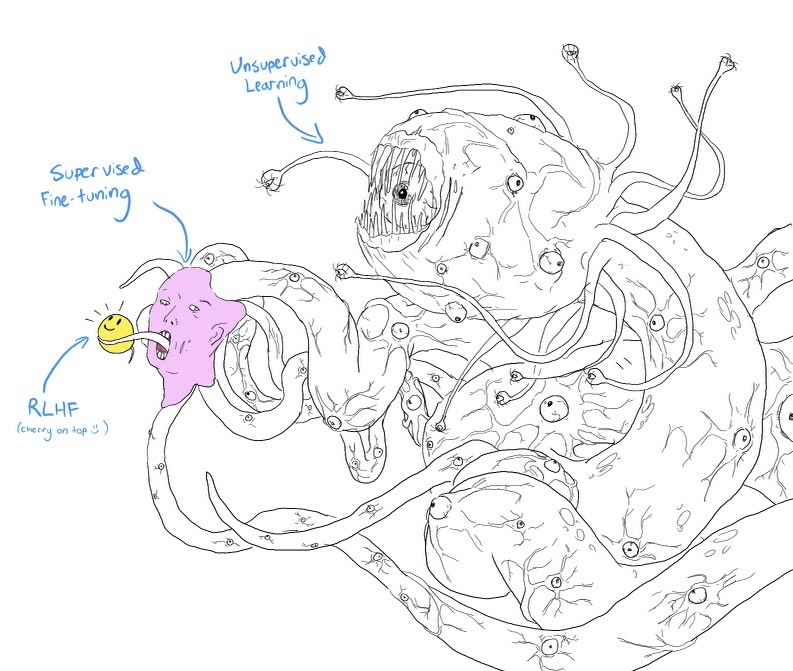
Veamos estas tres fases con un poco más de detalle. En primer lugar, el preentrenamiento no supervisado le permite al modelo aprender todo lo que sabe del mundo, le dota de su conocimiento y de su inteligencia, pues tras la aparentemente inocua tarea de predecir la siguiente palabra, la IA necesitará aprender que el libro más famoso de Platón es La República, que los Beatles fueron una figura revolucionaria en la música en la década de los 60, deberá poder resolver problemas de lógica, realizar una plan de acción para lograr un objetivo, o realizar un diagnóstico médico diferencial. Ahora bien, este preentrenamiento no es suficiente; un modelo tal es aún salvaje y puede producir resultados impredecibles: ante una pregunta podría elegir contestarla, pero también completar el texto planteando más preguntas relacionadas, o adoptar el punto de vista de un troll de internet en la respuesta. GPT ha visto todo, y eso lo hace inteligente, pero a la hora de usarlo no queremos que conteste cualquier cosa, sino que lo haga tal que sea útil como chatbot, y es por ello que se entrena de forma supervisada con realimentación humana, simplemente para convencerlo de actuar de un modo específico. La siguiente imagen (por Helen Toner, en Twitter) muestra el proceso de pensamiento de chat-GPT como un monstruo inhumano Lovecraftiano de múltiples cabezas, al que etapas posteriores de entrenamiento supervisado dibujan una cara amigable con la que interaccionar. La realidad es que el proceso de hacerlo más “amigable” y más “seguro” es una suerte de lobotomía digital, que también cercena las capacidades del modelo9.
GPT-4 además añade la posibilidad de proporcionar imágenes junto con el texto como entrada. Para ello, parte cada imagen en trozos, y convierte cada uno de ellos en un token para después ser procesado como si de texto se tratara (el artículo que primero propuso esta técnica se titula apropiadamente: “An image is worth 16×16 words”11). Con o sin imágenes, la realidad es que GPT-4 es extremadamente capaz. En su technical report7, GPT-4 se pone a prueba en una variedad de exámenes y tareas cognitivas, comparando posteriormente su rendimiento con el de los humanos. Los resultados son arrolladores: GPT-4 logra una puntuación en el percentil 90% en los Bar Exam, un examen que los graduados en derecho deben superar para poder ser admitidos en el colegio de abogados y obtener la licencia para ejercer; o una nota del 86.4% en el conjunto de preguntas MMLU, una prueba que abarca 57 tareas, entre ellas matemáticas elementales, historia de Estados Unidos, informática y derecho, y que requiere poseer amplios conocimientos del mundo y alta capacidad para resolver problemas12. GPT-4 también ha “visto” mucho código durante su entrenamiento, y es por tanto capaz de programar con un nivel de competencia muy elevado.

Pero eso no es todo, con GPT surge también un nuevo arte: prompt design, o la capacidad de generar consultas de tal forma que el mismo modelo produzca mejores respuestas. Por ejemplo, simplemente con añadir “Let’s work this out in a step by step way to be sure we have the right answer” al final de la consulta, el rendimiento de GPT-4 mejora significativamente en todo tipo de tareas13. Del mismo modo, pidiéndole al modelo que reflexione sobre sus respuestas anteriores, liste sus fallos y virtudes, y elija la mejor, se logra también mejorar su rendimiento14. Esto no es sorprendente, puesto que la forma avariciosa de generación de texto empleada por GPT (un token a la vez) impide al modelo ir atrás y corregir razonamientos iniciales que podían ser erróneos; en cambio, permitiéndole utilizar su salida anterior como base sobre la que iterar, GPT supera esta limitación.
De forma similar, darle a GPT-4 acceso a herramientas resuelve muchas de sus limitaciones. Por ejemplo, clásicamente GPT-4 ha tenido problemas para resolver operaciones matemáticas (porque los tokens están optimizados para texto y no para matemáticas, y porque incluso algoritmos sencillos como el de la suma requieren calcular la respuesta de atrás hacia delante, cosa con la que los modelos GPT tienen dificultades), sin embargo, simplemente indicándole a GPT-4 que tiene acceso a una calculadora, y mostrándole por texto la sintaxis de una consulta, el modelo sabe de inmediato utilizar dicha herramienta cada vez que necesita realizar una operación compleja. Del mismo modo, aunque el conocimiento del mundo de GPT-4 está limitado temporalmente a los datos con los que fue entrenado, simplemente dándole acceso a un buscador de internet esta limitación desaparece.
Sobre esta idea, comienzan ya a surgir aplicaciones basadas en GPT-4 con el potencial de revolucionar el mercado del trabajo. Por ejemplo, Auto-GPT15 es un sistema que, dada una tarea especificada por el usuario (por ejemplo: escribir una aplicación para el móvil, pedir una pizza, o hacer investigación en cierto tema16), es capaz de crear un plan de acción y ejecutarlo paso a paso, utilizando para ello herramientas que le permiten ejecutar código (y leer las salidas, depurarlo, etc.), enviar correos, o consultar internet. Otro ejemplo es langchain17, una librería que automatiza el proceso de, dada una consulta concreta, buscar en grandes documentos de texto (véase normativa, jurisprudencia, documentación interna de una empresa), y generar un informe resumiendo los hallazgos, incluyendo referencias al texto original. Del mismo modo que los modelos de generación de imágenes van necesariamente a recortar trabajo a los artistas (a pesar de que el arte generada por humanos siempre será subjetivamente más valiosa18), no es difícil imaginar muchas profesiones que también sufrirán con estos modelos del lenguaje: profesores, escritores, periodistas, pero también programadores, abogados, etc.

Un reciente informe de Open AI, la empresa creadora de ChatGPT, predice que aproximadamente la mitad de los trabajos en E.E.U.U se volverán más eficientes mediante el uso de herramientas construidas sobre GPT-420, Goldman Sachs predice que además de una subida de productividad, en torno a un 7% de los trabajos desaparecerán21, y el director ejecutivo de IBM, Arvind Krishna, afirma que, en IBM, hasta el 30% de los puestos no orientados al cliente serán reemplazados por IAs. Sam Altman, director ejecutivo de OpenAI, escribía en su blog: “El precio de muchos tipos de mano de obra (que impulsa los costes de bienes y servicios) caerá hacia cero una vez que una IA suficientemente potente se una a la mano de obra” y propone una suerte de renta básica universal como solución22. Si además consideramos avances futuros (pero no tan lejanos) en IA personificada (es decir, integrada en robots físicos, en los cuales varias empresas ya están trabajando23,24), cualquier trabajo pasa a ser susceptible de ser automatizado. Todavía no estamos ahí, pero no hay que olvidar que esta tecnología está aún en su más tierna infancia, y que tendemos a subestimar la rapidez del crecimiento exponencial.
A principios de mayo de 2023, Geoffrey Hinton, uno de los padres indiscutibles de la IA abandonó su puesto en Google, con declaraciones como “Ahora mismo, [los chatbots] no son más inteligentes que nosotros, que yo sepa. Pero creo que pronto podrían serlo […]. Así que tenemos que preocuparnos por eso”25. El 16 de mayo, Sam Altman testificó frente al Senado de los E.E.U.U, demandando mayor regulación para los LLMs, clasificándolos regulatoriamente en base a criterios tales como su capacidad de auto-replicación o a sus capacidades para manipular, crear nuevas armas biológicas, etc26. Aunque no es inhabitual que las empresas aboguen por la regulación cuando esta ya es inevitable, parece que Altman es sincero, y lleva bastante tiempo escribiendo y promoviendo la investigación en el problema de la alineación (a saber, entre los valores e intereses de los seres humanos y los de las IAs que creamos).
Para cerrar, me gustaría volver a la carta abierta a la moratoria del entrenamiento de nuevos LLMs que se ha introducido al principio. Esta continúa: “¿Deberíamos automatizar todos los trabajos, incluidos los más gratificantes? ¿Debemos desarrollar mentes no humanas que, con el tiempo, nos superen en número, inteligencia, obsolescencia y reemplazo? ¿Debemos arriesgarnos a perder el control de nuestra civilización? […] La reciente declaración de OpenAI en relación con la inteligencia artificial general, afirma que «En algún momento, puede ser importante obtener una revisión independiente antes de empezar a entrenar futuros sistemas, y que los esfuerzos más avanzados acuerden limitar la tasa de crecimiento de la computación utilizada para crear nuevos modelos.» Estamos de acuerdo. Ese momento es ahora”. Tan solo un mes después de firmar esta carta, Elon Musk ha fundado su nueva empresa de IA, X.AI, presumiblemente para competir con OpenAI27. En efecto, no falta alimento para el cinismo, pero la realidad es que, si la inteligencia artificial general realmente viene de la mano de escalar transformers como hasta ahora, probablemente ya estamos todos muertos.
Escrito por Oscar J. Pellicer Valero
Que buena lectura, !gracias Oscar! Me pregunto en qué momento incluso el trabajo de investigación se reduce a ser un assistant de un LLM que puede generar hipótesis y probarlas (con nuestra tarea siendo de recoger los datos in situ). Espero que no sea demasiado cerca. Sin embargo, es interesante ver cómo tradicionalmente se sustituían los trabajos físicos por los mentales. Esta vez parece que es al revés.